记录一下在codewars上面做到python练习题以及一些笔记
001 迭代+条件
Implement the function unique_in_order which takes as argument a sequence and returns a list of items without any elements with the same value next to each other and preserving the original order of elements.
For example:
1 | unique_in_order('AAAABBBCCDAABBB') == ['A', 'B', 'C', 'D', 'A', 'B'] |
Solution
1 | def unique_in_order(iterable): |
涉及知识:
1)python 迭代:iter()返回迭代器
2)append 在列表末添加新对象,并作为新的result(这个没想到)
emmm刚才那个没有解决空数组的情况,看了新的解答
1 | def unique_in_order(iterable): |
这个似乎比较好理解,用了for循环和if条件
002 Exes and Ohs
Check to see if a string has the same amount of ‘x’s and ‘o’s. The method must return a boolean and be case insensitive. The string can contain any char.
Examples input/output:
1 | XO("ooxx") => true |
Solution
1 | def xo(s): |
嗯嗯嗯第一个完全自己改出来的没有错的!恭喜—— 虽然是比较笨的办法
来看看最优解法吧:
1 | def xo(s): |
.lower可以大写变小写
另外还用到了count函数,记住了(记住了
003 Sum of odd numbers
Given the triangle of consecutive odd numbers:
1 | 1 |
Calculate the sum of the numbers in the nth row of this triangle (starting at index 1) e.g.: (Input –> Output)
1 | 1 --> 1 |
Solution
1 | def row_sum_odd_numbers(n): |
就是简单粗暴的数学题吧。。。
004 Find the missing letter
#Find the missing letter
Write a method that takes an array of consecutive (increasing) letters as input and that returns the missing letter in the array.
You will always get an valid array. And it will be always exactly one letter be missing. The length of the array will always be at least 2.
The array will always contain letters in only one case.
Example:
[‘a’,’b’,’c’,’d’,’f’] -> ‘e’ [‘O’,’Q’,’R’,’S’] -> ‘P’
1 | ["a","b","c","d","f"] -> "e" |
(Use the English alphabet with 26 letters!)
Have fun coding it and please don’t forget to vote and rank this kata! :-)
I have also created other katas. Take a look if you enjoyed this kata!
Solution
1 | def find_missing_letter(chars): |
ord :chr() 函数(对于8位的ASCII字符串)或unichr() 函数(对于Unicode对象)的配对函数
*分清题目中的chars和chr
005 Multiples of 3 or 5
If we list all the natural numbers below 10 that are multiples of 3 or 5, we get 3, 5, 6 and 9. The sum of these multiples is 23.
Finish the solution so that it returns the sum of all the multiples of 3 or 5 below the number passed in. Additionally, if the number is negative, return 0 (for languages that do have them).
Note: If the number is a multiple of both 3 and 5, only count it once.
Solution
1 | def solution(number): |
恩恩额又是比较笨的解法
1 | def solution(number): |
最短的解法,其实思路是一样的嘛
006 String ends with?
Complete the solution so that it returns true if the first argument(string) passed in ends with the 2nd argument (also a string).
Examples:
1 | solution('abc', 'bc') # returns true |
Solution
1 | def solution(string, ending): |
自己做出来了——
更好的解法:
1 | def solution(string, ending): |
.endwith 用来专门判断是否以某个字符串结尾
007 Bit Counting
Write a function that takes an integer as input, and returns the number of bits that are equal to one in the binary representation of that number. You can guarantee that input is non-negative.
Example: The binary representation of 1234 is 10011010010, so the function should return 5 in this case
Solution
1 | def count_bits(n): |
嗯嗯直接用了count函数
008 Sum of two lowest positive integers
Create a function that returns the sum of the two lowest positive numbers given an array of minimum 4 positive integers. No floats or non-positive integers will be passed.
For example, when an array is passed like [19, 5, 42, 2, 77], the output should be 7.
[10, 343445353, 3453445, 3453545353453] should return 3453455.
Solution
1 | def sum_two_smallest_numbers(numbers): |
remove() 函数用于移除列表中某个值的第一个匹配项
009 Shortest Word
Simple, given a string of words, return the length of the shortest word(s).
String will never be empty and you do not need to account for different data types.
Solution
1 | def find_short(s): |
010 Moving Zeros To The End
Write an algorithm that takes an array and moves all of the zeros to the end, preserving the order of the other elements.
1 | move_zeros([1, 0, 1, 2, 0, 1, 3]) # returns [1, 1, 2, 1, 3, 0, 0] |
Solution
1 | def move_zeros(lst): |
匿名函数lambda:是指一类无需定义标识符(函数名)的函数或子程序
011 Duplicate Encoder
The goal of this exercise is to convert a string to a new string where each character in the new string is "(" if that character appears only once in the original string, or ")" if that character appears more than once in the original string. Ignore capitalization when determining if a character is a duplicate.
Examples
1 | "din" => "(((" |
Notes
Assertion messages may be unclear about what they display in some languages. If you read "...It Should encode XXX", the "XXX" is the expected result, not the input!
Solution
1 | def duplicate_encode(word): |
还是使用了循环读取的老办法,使用了新的:
str = '' return (str.join(result))
将列表转化为字符串,str里面是连接词。
另外注意先.lower 转为小写
大佬的解法:
1 | def duplicate_encode(word): |
嗯嗯嗯有点太长了转不过来
012 Delete occurrences of an element if it occurs more than n times
Enough is enough!
Alice and Bob were on a holiday. Both of them took many pictures of the places they’ve been, and now they want to show Charlie their entire collection. However, Charlie doesn’t like these sessions, since the motif usually repeats. He isn’t fond of seeing the Eiffel tower 40 times.
He tells them that he will only sit for the session if they show the same motif at most N times. Luckily, Alice and Bob are able to encode the motif as a number. Can you help them to remove numbers such that their list contains each number only up to N times, without changing the order?
Task
Given a list and a number, create a new list that contains each number of list at most N times, without reordering.
For example if the input number is 2, and the input list is [1,2,3,1,2,1,2,3], you take [1,2,3,1,2], drop the next [1,2] since this would lead to 1 and 2 being in the result 3 times, and then take 3, which leads to [1,2,3,1,2,3].
With list [20,37,20,21] and number 1, the result would be [20,37,21].
Solution
1 | def delete_nth(order,max_e): |
这个虽然做出来了但是总觉得条件那里应该是数量<=max_e,但是用<做出来才是正确的,为什么呢….
.count 和 .append基本上能用上手了
看了看大佬的解答似乎差不多,对于列表中的元素似乎可以直接用 for o in order 来依次点到
013 Consecutive strings
1 | Concatenate the consecutive strings of strarr by 2, we get: |
n being the length of the string array, if n = 0 or k > n or k <= 0 return “” (return Nothing in Elm, “nothing” in Erlang).
Note
consecutive strings : follow one after another without an interruption
Solution
这题感觉好难,做了半个多小时都不对,放弃了。。。
自己的解答:
1 | def longest_consec(strarr, k): |
合起来j的循环那里会出问题,还会有报错list index out of range
别人的解答:
1 | def longest_consec(strarr, k): |
014 PaginationHelper
For this exercise you will be strengthening your page-fu mastery. You will complete the PaginationHelper class, which is a utility class helpful for querying paging information related to an array.
The class is designed to take in an array of values and an integer indicating how many items will be allowed per each page. The types of values contained within the collection/array are not relevant.
The following are some examples of how this class is used:
1 | helper = PaginationHelper(['a','b','c','d','e','f'], 4) |
Solution
1 | class PaginationHelper: |
姑且看别人的学习一些语法之后自己能独立写出思路来。第一次接触到一个函数class。
在同一个class中使用self.xxx来调用之前的函数,依旧是逻辑题,注意在count时是否需要+1或-1
015 Human Readable Time(补0&输出格式
Write a function, which takes a non-negative integer (seconds) as input and returns the time in a human-readable format (HH:MM:SS)
HH= hours, padded to 2 digits, range: 00 - 99MM= minutes, padded to 2 digits, range: 00 - 59SS= seconds, padded to 2 digits, range: 00 - 59
The maximum time never exceeds 359999 (99:59:59)
You can find some examples in the test fixtures.
Solution
1 | def make_readable(seconds): |
本来是非常简单的问题,到了结果输出这里整的非常想死。。。本来想用:join连接结果一直有bug也查不出来是怎么改,干脆用了笨笨办法,应该是c的东西了吧。其他主要还用到了a = "%02d" % h在数字前面补0
贴一下大佬的笔记↓↓↓
python中有一个zfill方法用来给字符串前面补0,非常有用
1 | n ``=` `"123" |
zfill()也可以给负数补0
1 | n ``=` `"-123" |
对于纯数字,我们也可以通过格式化的方式来补0
1 | n ``=` `123 |
好了最后来看看大佬的解法吧
1 | def make_readable(s): |
嗯嗯嗯简单到想死呢()对啊我为什么不直接除3600(orz
016 RGB To Hex Conversion
The rgb function is incomplete. Complete it so that passing in RGB decimal values will result in a hexadecimal representation being returned. Valid decimal values for RGB are 0 - 255. Any values that fall out of that range must be rounded to the closest valid value.
Note: Your answer should always be 6 characters long, the shorthand with 3 will not work here.
The following are examples of expected output values:
1 | rgb(255, 255, 255) # returns FFFFFF |
Solution
1 | def rgb(r, g, b): |
前面的if还是笨笨的办法(),后面用到了新的hex()将十进制转化为16进制,
顺便贴一下其他进制转换的方法:
十六进制 到 十进制
int(‘0xf’,16)
→15
二进制 到 十进制
int(‘10100111110’,2)
→1342
八进制 到 十进制
int(‘17’,8)
→15
十进制 转 十六进制
hex(1033)
→’0x409’
二进制 转 十六进制
hex(int(‘101010’,2))
→’0x2a’
八进制到 十六进制
hex(int(‘17’,8))
→’0xf’
转二进制则是用bin(),八进制用oct()
另外输出格式和补0还是烦恼了一会儿。
看看大佬的解法吧
1 | def rgb(r, g, b): |
lambda函数【lambda函数没有名字,是一种简单的、在同一行中定义函数的方法】说实话还是没看太明白,大概是执行单行中的命令的函数
这个min max用的好聪明啊——
后面输出用的.format是代替从前的%s这样的东西
017 Calculating with Functions
This time we want to write calculations using functions and get the results. Let’s have a look at some examples:
1 | seven(times(five())) # must return 35 |
Requirements:
- There must be a function for each number from 0 (“zero”) to 9 (“nine”)
- There must be a function for each of the following mathematical operations: plus, minus, times, divided_by
- Each calculation consist of exactly one operation and two numbers
- The most outer function represents the left operand, the most inner function represents the right operand
- Division should be integer division. For example, this should return
2, not2.666666...:
1 | def zero(f = None): return 0 if not f else f(0) |
这题实在没头绪抄作业了(然后作业也还没怎么看懂)
if not 用来判断变量是否为None;if not … else则与if 相反
里面和外面还是搞不太懂。。。晕了
018 Count IP Addresses
Implement a function that receives two IPv4 addresses, and returns the number of addresses between them (including the first one, excluding the last one).
All inputs will be valid IPv4 addresses in the form of strings. The last address will always be greater than the first one.
Examples
1 | * With input "10.0.0.0", "10.0.0.50" => return 50 |
Solution
1 | def ips_between(start, end): |
自己算是成功解出来了。主要在于split(“.”, 4)这里,前面是分割符号,后面是分割个数,但是分完之后每个元素是str属性,所以在下面计算的时候需要转为int,算式显得有点麻烦。
另外有个小问题,算256的倍数的时候直接写(256^3)好像算出来不对,这是为什么呢。。。嗯嗯嗯好的查了一下发现次方运算符是**,而不是像c里面那样的^
来看看大佬的解法吧
1 | from ipaddress import ip_address |
原来如此直接转int再减就好了吗!好吧
用到了from import,好像是直接把整体模块对象引用过来。如果要一次导入所有可以引用的函数(有点难以理解),可以用
1 | from math import * |
这样的。
019 Greed is Good
Greed is a dice game played with five six-sided dice. Your mission, should you choose to accept it, is to score a throw according to these rules. You will always be given an array with five six-sided dice values.
1 | Three 1's => 1000 points |
A single die can only be counted once in each roll. For example, a given “5” can only count as part of a triplet (contributing to the 500 points) or as a single 50 points, but not both in the same roll.
Example scoring
1 | Throw Score |
In some languages, it is possible to mutate the input to the function. This is something that you should never do. If you mutate the input, you will not be able to pass all the tests.
Solution
1 | def score(dice): |
这个是自己的解答,但是总是有哪里少加了一点不太对,也不知道是哪里不对
恩恩额想不出来哪里错了可恶——有两个少了1000但是我觉得前面3个1那里应该没问题啊多洗爹
好的我知道了前面的3个加分那里应该把if dice.count(i) == 3:改成if dice.count(i) >= 3:就好了,好吧(后面改好了)
一开始前面还是用的一个一个if的笨办法,后面稍微改了一下用上了循环,后面还是稍微有点繁琐
还是来看看大佬的解法吧
1 | def score(dice): |
用到了enumerate(枚举),在for (i, count) in enumerate(counter):中即表示同时列举i(项数)与count(元素值)。虽然具体用法看起来还是很复杂orz
还聪明的用了取余数
020 Rot13
ROT13 is a simple letter substitution cipher that replaces a letter with the letter 13 letters after it in the alphabet. ROT13 is an example of the Caesar cipher.
Create a function that takes a string and returns the string ciphered with Rot13. If there are numbers or special characters included in the string, they should be returned as they are. Only letters from the latin/english alphabet should be shifted, like in the original Rot13 “implementation”.
Please note that using encode is considered cheating.
Solution
1 | def rot13(message): |
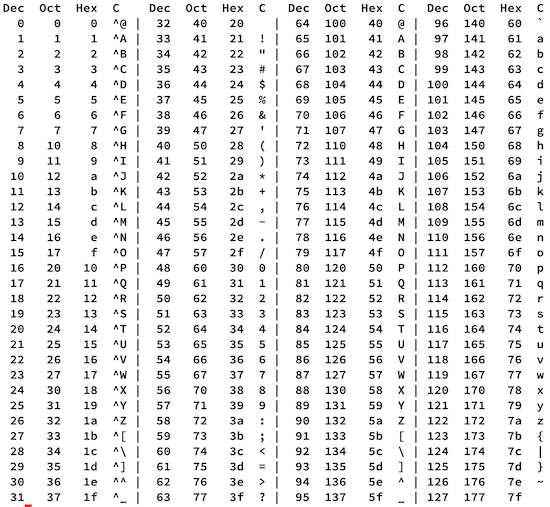
附一个ASCII表
这题还算简单,考虑+13-13和不变的三类就ok
021 Who likes it?
You probably know the “like” system from Facebook and other pages. People can “like” blog posts, pictures or other items. We want to create the text that should be displayed next to such an item.
Implement the function which takes an array containing the names of people that like an item. It must return the display text as shown in the examples:
1 | [] --> "no one likes this" |
Note: For 4 or more names, the number in "and 2 others" simply increases.
Solution
1 | def likes(names): |
这题蛮顺利的自己写出来了,还挺有趣的功能。还是用了%s和%d
看看大佬的解法
1 | def likes(names): |
使用了.format,看起来很清楚简洁!下次试试
(之前刷了点简单的题没记录,后面遇到有趣的或者比较难的再记录吧
022 Two to One
Take 2 strings s1 and s2 including only letters from a to z. Return a new sorted string, the longest possible, containing distinct letters - each taken only once - coming from s1 or s2.
Examples:
1 | a = "xyaabbbccccdefww" |
Solution
1 | def longest(a1, a2): |
这题开始在思路上还苦恼了一下
看看大佬的解法
1 | def longest(a1, a2): |
set()创建无序不重复元素集
sorted()对列表、集合、字符串等等进行排序,升序为默认(False),可改成降序(True),最后join一下
023 List Filtering
In this kata you will create a function that takes a list of non-negative integers and strings and returns a new list with the strings filtered out.
Example
1 | filter_list([1,2,'a','b']) == [1,2] |
Solution
1 | def filter_list(l): |
用到了新学的判断数据类型的函数 isinstance(a,(str,int,list))
024 Your order, please
Your task is to sort a given string. Each word in the string will contain a single number. This number is the position the word should have in the result.
Note: Numbers can be from 1 to 9. So 1 will be the first word (not 0).
If the input string is empty, return an empty string. The words in the input String will only contain valid consecutive numbers.
Examples
1 | "is2 Thi1s T4est 3a" --> "Thi1s is2 3a T4est" |
Solution
1 | def order(sentence): |
这题自己苦恼了很久最后还是做出来了,虽然感觉是比较笨的办法应该绕了点弯路。一共叠了三层循环。最开始是把 for i in a 放在最外面的,后面发现这样的话,如果位置在前面的项不是1、2之类的话,就会直接被跳过,后面输出的时候就没有3、4了。于是乎改成循环从寻找1开始,每次都从a的开头开始找,虽然有些笨重但是好歹没错。
另外在比较条件的时候需要 if n == str(i+1) ,没有加str的话做出来是空的。。。
看了大佬们的解法,有一个用了lambda就不提了,比较关注的是用了下面这个的:
1 | if str(i) in item: |
if 这个数字在字符串里面,学到了新的判断方式(大拇指
025 Stack cans into pyramids
In this kata you will be solving a problem of a store worker that specializes in stacking cans in pyramid shapes in stores, he only makes a pyramid with square bases and always puts a can on top of other 4 cans his problem is that sometimes does not get exact amount so he has to either buy more or return some. (He will do what is easier)
Your task is to calculate the number he will return or buy.
Example: 3 cans -> 1 can or 5 cans (1-4) both result are same distance so he will return or buy 2
10 cans -> 5 cans (1-4) or 14 cans (1-4-9) he will return 4 cans since 14 is closer to 10
As our worker is really dedicated he can obtain up to 1 +15e cans
Solution
1 | def perfect_pyramid(cans): |
这个beta题还做了挺久。循环思考起来稍微有点复杂,一开始还引入了sum来计算平方和,后面发现这样挨个减掉之后并用不上orz
不确定怎么解决的时候就先整几个参数然后调出来看看是啥吧,说不定就发现解法了(
026 Decode the Morse code
In this kata you have to write a simple Morse code decoder. While the Morse code is now mostly superseded by voice and digital data communication channels, it still has its use in some applications around the world.
The Morse code encodes every character as a sequence of “dots” and “dashes”. For example, the letter A is coded as ·−, letter Q is coded as −−·−, and digit 1 is coded as ·−−−−. The Morse code is case-insensitive, traditionally capital letters are used. When the message is written in Morse code, a single space is used to separate the character codes and 3 spaces are used to separate words. For example, the message HEY JUDE in Morse code is ···· · −·−− ·−−− ··− −·· ·.
NOTE: Extra spaces before or after the code have no meaning and should be ignored.
In addition to letters, digits and some punctuation, there are some special service codes, the most notorious of those is the international distress signal SOS (that was first issued by Titanic), that is coded as ···−−−···. These special codes are treated as single special characters, and usually are transmitted as separate words.
Your task is to implement a function that would take the morse code as input and return a decoded human-readable string.
For example:
1 | decode_morse('.... . -.-- .--- ..- -.. .') |
NOTE: For coding purposes you have to use ASCII characters . and -, not Unicode characters.
The Morse code table is preloaded for you as a dictionary, feel free to use it:
Coffeescript/C++/Go/JavaScript/Julia/PHP/Python/Ruby/TypeScript:
MORSE_CODE['.--']C#:
MorseCode.Get(".--")(returnsstring)F#:
MorseCode.get ".--"(returnsstring)Elixir:
@morse_codesvariable (fromuse MorseCode.Constants). Ignore the unused variable warning formorse_codesbecause it’s no longer used and kept only for old solutions.Elm:
MorseCodes.get : Dict String StringHaskell:
morseCodes ! ".--"(Codes are in aMap String String)Java:
MorseCode.get(".--")Kotlin:
MorseCode[".--"] ?: ""orMorseCode.getOrDefault(".--", "")Racket:
morse-code(a hash table)Rust:
MORSE_CODEScala:
morseCodes(".--")Swift:
MorseCode[".--"] ?? ""orMorseCode[".--", default: ""]C: provides parallel arrays, i.e.
morse[2] == "-.-"forascii[2] == "C"NASM: a table of pointers to the morsecodes, and a corresponding list of ascii symbols
All the test strings would contain valid Morse code, so you may skip checking for errors and exceptions. In C#, tests will fail if the solution code throws an exception, please keep that in mind. This is mostly because otherwise the engine would simply ignore the tests, resulting in a “valid” solution.
Good luck!
Solution
1 | def decode_morse(morse_code): |
摩斯电码解码!酷酷
开始有点小问题,因为忘记了第一步的去掉左右空格,后面倒是没什么大问题
027 Pete, the baker
Pete likes to bake some cakes. He has some recipes and ingredients. Unfortunately he is not good in maths. Can you help him to find out, how many cakes he could bake considering his recipes?
Write a function cakes(), which takes the recipe (object) and the available ingredients (also an object) and returns the maximum number of cakes Pete can bake (integer). For simplicity there are no units for the amounts (e.g. 1 lb of flour or 200 g of sugar are simply 1 or 200). Ingredients that are not present in the objects, can be considered as 0.
Examples:
1 | # must return 2 |
Solution
1 | def cakes(recipe, available): |
好久没接触字典了,查查改改还是做出来了。一开始想着再把字典改成列表用,反而变复杂了….!
用到了一些关于dict的基本操作,比如直接的for i in dict是返回字典里各个键,要返回values的话应该用dict.values()。另外要看某个键的value的话直接用dict[‘key name’]就可以了
看看大佬的解法:
1 | def cakes(recipe, available): |
对于我来说还太高级了——
028 Integers: Recreation One
1, 246, 2, 123, 3, 82, 6, 41 are the divisors of number 246. Squaring these divisors we get: 1, 60516, 4, 15129, 9, 6724, 36, 1681. The sum of these squares is 84100 which is 290 * 290.
Task
Find all integers between m and n (m and n integers with 1 <= m <= n) such that the sum of their squared divisors is itself a square.
We will return an array of subarrays or of tuples (in C an array of Pair) or a string. The subarrays (or tuples or Pairs) will have two elements: first the number the squared divisors of which is a square and then the sum of the squared divisors.
Example:
1 | list_squared(1, 250) --> [[1, 1], [42, 2500], [246, 84100]] |
The form of the examples may change according to the language, see “Sample Tests”.
Note
In Fortran - as in any other language - the returned string is not permitted to contain any redundant trailing whitespace: you can use dynamically allocated character strings.
SOLUTION
1 | def list_squared(m, n): |
自己做出来了——
思考上稍微有点点绕,最后还需要把自己本身能开方的去掉一个平方根,为什么呢(为什么呢)